《使用 Shell 脚本实现 Docker》旨在通过一系列的实验使用户对docker的底层技术,如Namespace、CGroups、rootfs、联合加载等有一个感性的认识。在此过程中,我们还将通过Shell脚本一步一步地实现一个简易的docker,以期使读者在使用docker的过程中知其然知其所以然。
我们的实验环境为Ubuntu 18.04 64bit,简易docker工程的名字为 docker.sh,该工程仓库地址如下:
https://github.com/pandengyang/docker.sh.git
https://github.com/appotry/docker.sh《使用 Shell 脚本实现 Docker》目录如下:
1. Namespace
1.1. Namespace简介
1.2. uts namespace
1.2.1. uts namespace简介
1.2.2. docker.sh
1.3. mount namespace
1.3.1. /etc/mtab、/proc/self/mounts
1.3.2. /proc/self/mountinfo
1.3.3. bind mount
1.3.4. mount namespace简介
1.3.5. docker.sh
1.4. pid namespace
1.4.1. unshare的--fork选项
1.4.2. pid namespace简介
1.4.3. pid嵌套
1.4.4. docker.sh
2. CGroups
2.1. CGroups简介
2.2. 限制内存
2.2.1. 用CGroups限制内存
2.2.2. docker.sh
3. 切换根文件系统
3.1. 根文件系统
3.2. pivot_root
3.3. docker.sh
4. 联合加载
4.1. 联合加载简介
4.2. AUFS
4.3. docker.sh
5. 卷
5.1. 卷简介
5.2. docker.sh
6. 后记Namespace
Namespace简介
传统上,在Linux中,许多资源是全局管理的。例如,系统中的所有进程按照惯例是通过PID标识的,这意味着内核必须管理一个全局的PID列表。而且,所有调用者通过uname系统调用返回的系统相关信息都是相同的。用户id的管理方式类似,即各个用户是通过一个全局唯一的UID标识。
Namespace是Linux用来隔离上述全局资源的一种方式。把一个或多个进程加入到同一个namespace中后,这些进程只会看到该namespace中的资源。namespace是后来加入到Linux中的,为了兼容之前的全局资源管理方式,Linux为每一种资源准备了一个全局的namespace。Linux中的每一个进程都默认加入了这些全局namespace。
Linux中的每个进程都有一个/proc/[pid]/ns/目录,里面包含了该进程所属的namespace信息。我们查看一下当前Shell的/proc/[pid]/ns目录,命令及结果如下:
phl@kernelnewbies:~$ sudo ls -l /proc/$$/ns
total 0
lrwxrwxrwx 1 phl phl 0 Jan 22 08:43 cgroup -> cgroup:[4026531835]
lrwxrwxrwx 1 phl phl 0 Jan 22 08:43 ipc -> ipc:[4026531839]
lrwxrwxrwx 1 phl phl 0 Jan 22 08:43 mnt -> mnt:[4026531840]
lrwxrwxrwx 1 phl phl 0 Jan 22 08:43 net -> net:[4026531993]
lrwxrwxrwx 1 phl phl 0 Jan 22 08:43 pid -> pid:[4026531836]
lrwxrwxrwx 1 phl phl 0 Jan 22 08:43 pid_for_children -> pid:[4026531836]
lrwxrwxrwx 1 phl phl 0 Jan 22 08:43 user -> user:[4026531837]
lrwxrwxrwx 1 phl phl 0 Jan 22 08:43 uts -> uts:[4026531838]该目录下有很多符号链接,每个符号链接代表一个该进程所属的namespace。用readlink读取这些符号链接可以查看进程所属的namespace id。我们读一下当前Shell所属的uts namespace id,命令及结果如下:
phl@kernelnewbies:~$ sudo readlink /proc/$$/ns/uts
uts:[4026531838]后文中我们将介绍uts namespace、mount namespace、pid namespace的用法。
uts namespace
uts namespace简介
uts namespace用于隔离系统的主机名等信息,我们将通过实验学习其用法。在实验过程中,我们采用如下的步骤:
- 查看全局uts namespace信息
- 新建一个uts namespace,查看其信息并作出修改
- 查看全局uts namespace,查看其是否被新建的uts namespace影响到
对于其他namespace,我们也采取类似的步骤进行实验学习。
首先,我们查看一下全局的hostname及uts namespace id。命令及结果如下:
phl@kernelnewbies:~$ hostname
kernelnewbies
phl@kernelnewbies:~$ sudo readlink /proc/$$/ns/uts
uts:[4026531838]然后,我们创建一个新的uts namespace,并查看其namespce id。
在继续之前,需要介绍一个namespace工具unshare。利用unshare我们可以新建一个的namespace,并在新namespace中执行一条命令。unshare执行时需要root权限。unshare的使用方法如下:
unshare [options] [program [arguments]]执行unshare时,我们可以指定要新建的namespace的类型以及要执行的命令。unshare提供了一系列选项,当指定某个选项时可新建指定的namespace。namespace类型选项如下:
- –uts创建新的uts namespace
- –mount创建新的mount namespace
- –pid创建新的pid namespace
- –user创建新的user namespace
介绍完unshare之后,我们继续之前的实验。我们用unshare创建一个新的uts namespace,并在新的uts namespace中执行/bin/bash命令,命令及结果如下:
phl@kernelnewbies:~$ sudo unshare --uts /bin/bash
root@kernelnewbies:~#我们用unshare创建了一个新的uts namespace。在新的uts namespace中查看其hostname和namespace id,命令及结果如下:
root@kernelnewbies:~$ hostname
kernelnewbies
root@kernelnewbies:~# readlink /proc/$$/ns/uts
uts:[4026532177]从结果我们可以看到,新uts namespace的id与全局uts namespace的id不一致。这说明/bin/bash已运行在一个新的uts namespace中了。
我们将新uts namespace的hostname改为dreamland,并强制更新Shell提示符。命令及结果如下:
root@kernelnewbies:~# hostname dreamland
root@kernelnewbies:~# hostname
dreamland
root@kernelnewbies:~# exec /bin/bash
root@dreamland:~#从结果我们可以看到,新uts namespace的hostname的确是被修改了,exec /bin/bash用于强制更新Shell的提示符。
我们重新打开一个Shell窗口,该Shell位于全局uts namespace中。在新的Shell窗口中查看全局uts namespace id及hostname,命令及结果如下:
phl@kernelnewbies:~$ hostname
kernelnewbies
phl@kernelnewbies:~$ sudo readlink /proc/$$/ns/uts
uts:[4026531838]从结果我们可以看到,我们在新uts namespace中所作的修改并未影响到全局的uts namespace。
父进程创建子进程时只有提供创建新namespace的标志,才可创建新的namespace,并使子进程处于新的namespace中。默认情况下,子进程与父进程处于相同的namespace中。我们在新的uts namespace中创建一个子进程,然后查看该子进程的uts namespace id,命令及结果如下:
phl@kernelnewbies:~$ sudo unshare --uts /bin/bash
root@kernelnewbies:~# readlink /proc/$$/ns/uts
uts:[4026532305]
root@kernelnewbies:~# bash
root@kernelnewbies:~# readlink /proc/$$/ns/uts
uts:[4026532305]从结果我们可以看到,子进程所属uts namespace的id与其父进程相同。其他namespae与uts namespace类似,子进程与父进程同属一个namespace。
docker.sh
有了以上关于uts namespace的介绍,我们就可以将uts namespace加入到docker.sh中了。docker.sh工程分为两个脚本:docker.sh和container.sh。
docker.sh用于收集用户输入、调用unshare创建namespace并执行container.sh脚本,docker.sh脚本如下:
#!/bin/bash
usage () {
echo -e "\033[31mIMPORTANT: Run As Root\033[0m"
echo ""
echo "Usage: docker.sh [OPTIONS]"
echo ""
echo "A docker written by shell"
echo ""
echo "Options:"
echo " -c string docker command"
echo " (\"run\")"
echo " -m memory"
echo " (\"100M, 200M, 300M...\")"
echo " -C string container name"
echo " -I string image name"
echo " -V string volume"
echo " -P string program to run in container"
return 0
}
if test "$(whoami)" != root
then
usage
exit -1
fi
while getopts c:m:C:I:V:P: option
do
case "$option"
in
c) cmd=$OPTARG;;
m) memory=$OPTARG;;
C) container=$OPTARG;;
I) image=$OPTARG;;
V) volume=$OPTARG;;
P) program=$OPTARG;;
\?) usage
exit -2;;
esac
done
export cmd=$cmd
export memory=$memory
export container=$container
export image=$image
export volume=$volume
export program=$program
unshare --uts ./container.sh脚本最开始为usage函数,该函数为docker.sh的使用说明。当用户以非预期的方式使用docker.sh时,该函数会被调用。该函数输出如下信息:
IMPORTANT: Run As Root
Usage: docker.sh [OPTIONS]
A docker written by shell
Options:
-c string docker command
("run")
-m memory
("100M, 200M, 300M...")
-C string container name
-I string image name
-V string volume
-P string program to run in container从usage函数的输出我们可以看到,执行docker.sh时需要root权限且需要正确地传递参数。
docker.sh首先对当前用户进行检测,如果用户不为root,则打印使用说明并退出脚本;如果用户为root,则继续执行。检测用户的脚本如下:
if test "$(whoami)" != root
then
usage
exit -1
fi然后,docker.sh使用getopts从命令行提取参数,然后赋值给合适的变量。从命令行提取参数的脚本如下:
while getopts c:m:C:I:V:P: option
do
case "$option"
in
c) cmd=$OPTARG;;
m) memory=$OPTARG;;
C) container=$OPTARG;;
I) image=$OPTARG;;
V) volume=$OPTARG;;
P) program=$OPTARG;;
\?) usage
exit -2;;
esac
done如果用户的输入不正确,则打印使用说明并退出脚本;如果用户输入正确,则解析命令行参数并赋值给合适的变量。
为了简化,用户在运行docker.sh时需提供完整的参数列表,示例如下:
sudo ./docker.sh -c run -m 100M -C dreamland -I ubuntu1604 -V data1 -P /bin/bash当然,如果当前用户就是root,就不需要sudo了。下表列出了各个参数的含义及示例:

docker.sh将命令行参数赋值给变量后,需要将这些变量导出,以传递给container.sh。导出变量的脚本如下:
export cmd=$cmd
export memory=$memory
export container=$container
export image=$image
export volume=$volume
export program=$program这里说明一下为什么要将docker.sh工程拆分为docker.sh和container.sh两个脚本。因为调用unshare创建新的namespace时,会执行一个命令,该命令在新的namespace中运行。该命令一旦结束,unshare也就结束了,unshare创建的新namespace也就不存在了。
docker.sh不会并发地执行unshare命令与unshare之后的脚本,因此,只有unshare结束了,后续脚本才可继续运行。但是当unshare结束了,准备执行后续脚本时,新的namespae已经不存在了。因此一些加入cgroups、切换根文件系统等工作必须在unshare执行的命令中进行,所以我们采用在unshare中执行container.sh脚本的方式完成后续的工作。
最后,docker.sh调用unshare创建新的uts namespace,并执行container.sh脚本。调用unshare的脚本如下:
unshare --uts ./container.shcontainer.sh将容器的hostname修改为通过-C传递的容器的名字,然后执行通过-P传递的程序。container.sh脚本如下:
#!/bin/bash
hostname $container
exec $program现在,我们运行docker.sh,并查看其hostname。命令及结果如下:
phl@kernelnewbies:~/docker.sh$ sudo ./docker.sh -c run -m 100M -C dreamland -I ubuntu1604 -V data1 -P /bin/bash
root@dreamland:~/docker.sh# hostname
dreamland从结果我们可以看到,容器的hostname已经改变为我们传递的容器名字dreamland了。
mount namespace
/etc/mtab、/proc/self/mounts
早期的Linux使用/etc/mtab文件来记录当前的挂载点信息。每次mount/umount文件系统时会更新/etc/mtab文件中的信息。
后来,linux引入了mount namespace,每个进程都有一份自己的挂载点信息。当然,处于同一个mount namespace里面的进程,其挂载点信息是相同的。进程的挂载点信息通过/proc/[pid]/mounts文件导出给用户。
为了兼容以前的/etc/mtab,/etc/mtab变成了指向/proc/self/mounts的符号链接。通过readlink查看/etc/mtab指向的文件,命令及结果如下:
phl@kernelnewbies:~$ readlink /etc/mtab
../proc/self/mounts通过读取/proc/self/mounts文件,可以查看当前的挂载点信息,命令及结果如下:
phl@kernelnewbies:~$ cat /proc/self/mounts
sysfs /sys sysfs rw,nosuid,nodev,noexec,relatime 0 0
proc /proc proc rw,nosuid,nodev,noexec,relatime 0 0
/dev/sda1 / ext4 rw,relatime,errors=remount-ro 0 0
securityfs /sys/kernel/security securityfs rw,nosuid,nodev,noexec,relatime 0 0
...由于该文件中内容太多,我们省略了一部分,只保留了一些比较重要的挂载点信息。每行的信息分为六个字段,各字段的含义及示例如下:
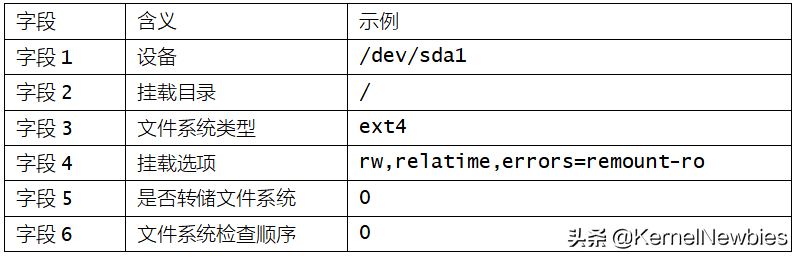
由于该文件有点过时,被后文介绍的/proc/self/mountinfo替换掉,所以不做过多介绍。
/proc/self/mountinfo
/proc/self/mountinfo包含了进程mount namespace中的挂载点信息。 它提供了旧的/proc/[pid]/mounts文件中缺少的各种信息(传播状态,挂载点id,父挂载点id等),并解决了/proc/[pid]/mounts文件的一些其他缺陷。我们查看进程挂载点信息时应优先使用该文件。
该文件中每一行代表一个挂载点信息,每个挂载点信息分为11个字段。挂载点信息的示例如下:

各字段的含义及示例如下:
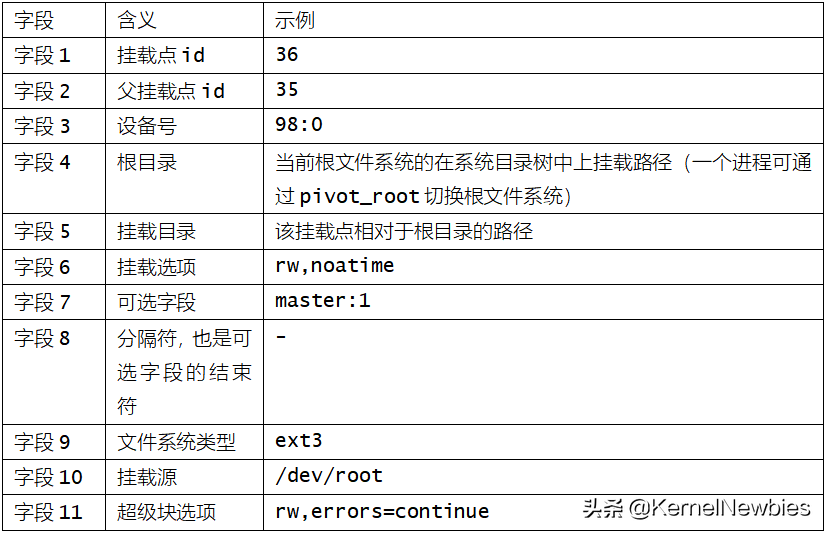
我们主要关注可选字段中的传播状态选项。首先,我们看一下关于mount namespace的问题。问题如下:
当创建mount namespace时,新mount namespace会拷贝一份老mount namespace里面的挂载点信息。例如,全局mount namespace中有一个/a挂载点,新建的mount namespace中也会有一个/a挂载点。那么我们在新mount namespace中的/a下创建或删除一个挂载点,全局mount namespace中的/a会同步创建或删除该挂载点吗?或者在全局mount namespace中的/a下创建或删除一个挂载点,新mount namespace中的/a会同步创建或删除该挂载点吗?
mountinfo文件中可选字段的传播状态就是控制在一个挂载点下进行创建/删除挂载点操作时是否会传播到其他挂载点的选项。传播状态有四种可取值,常见的有如下两种:
- shared 表示创建/删除挂载点的操作会传播到其他挂载点
- private 表示创建/删除挂载点的操作不会传播到其他挂载点
由于在容器技术中要保证主机与容器的挂载点信息互不影响,因此要求容器中的挂载点的传播状态为private。
1.3.3.bind mount
bind mount可以将一个目录(源目录)挂载到另一个目录(目的目录),在目的目录里面的读写操作将直接作用于源目录。
下面我们通过实验了解一下bind mount的功能,首先,我们准备一下实验所需要的的目录及文件。命令及结果如下:
phl@kernelnewbies:~$ mkdir bind
phl@kernelnewbies:~$ cd bind/
phl@kernelnewbies:~/bind$ mkdir a
phl@kernelnewbies:~/bind$ mkdir b
phl@kernelnewbies:~/bind$ echo hello, a > a/a.txt
phl@kernelnewbies:~/bind$ echo hello, b > b/b.txt然后,我们将a目录bind mount到b目录并查看b目录下的内容。命令及结果如下:
phl@kernelnewbies:~/bind$ sudo mount --bind a b
phl@kernelnewbies:~/bind$ tree b
b
└── a.txt
0 directories, 1 file从结果我们可以看到,b目录下原先的内容被隐藏,取而代之的是a目录下的内容。
然后,我们修改b目录下的内容,修改完毕后,从b目录上卸载掉a目录。命令及结果如下:
phl@kernelnewbies:~/bind$ echo hello, a from b > b/a.txt
phl@kernelnewbies:~/bind$ sudo umount b我们读取一下a目录中a.txt,看看其内容是否被改变。命令及结果如下:
phl@kernelnewbies:~/bind$ cat a/a.txt
hello, a from b从结果我们可以看到,a目录中的内容确实被当a被bind mount到b时对b目录的操作所修改了。
bind mount在容器技术中有很重要的用途,后文会有涉及。
mount namespace简介
mount namespace用来隔离文件系统的挂载点信息, 使得不同的mount namespace拥有自己独立的挂载点信息。不同的namespace之间不会相互影响,其在unshare中的选项为–mount。
当用unshare创建新的mount namespace时,新创建的namespace将拷贝一份老namespace里的挂载点信息,但从这之后,他们就没有关系了。这是unshare将新 namespace 里面的所有挂载点的传播状态设置为private实现的。通过mount和umount增加和删除各自mount namespace里面的挂载点都不会相互影响。
下面我们将演示mount namespace的用法。首先,我们准备需要的目录和文件,命令及结果如下:
phl@kernelnewbies:~$ mkdir -p hds/hd1 hds/hd2 && cd hds
phl@kernelnewbies:~/hds$ dd if=/dev/zero bs=1M count=1 of=hd1.img && mkfs.ext2 hd1.img
phl@kernelnewbies:~/hds$ dd if=/dev/zero bs=1M count=1 of=hd2.img && mkfs.ext2 hd2.img
phl@kernelnewbies:~$ tree .
.
├── hd1
├── hd1.img
├── hd2
└── hd2.img
2 directories, 2 files然后,我们在全局的mount namespace中挂载hd1.img到hd1目录,然后查看该mount namespace中的挂载点信息与mount namespace id。命令及结果如下:
phl@kernelnewbies:~/hds$ sudo mount hd1.img hd1
phl@kernelnewbies:~/hds$ cat /proc/self/mountinfo | grep hd
556 27 7:18 / /home/phl/hds/hd1 rw,relatime shared:372 - ext2 /dev/loop18 rw
phl@kernelnewbies:~/hds$ sudo readlink /proc/$$/ns/mnt
mnt:[4026531840]然后,执行unshare命令创建一个新的mount namespace并查看该mount namespace id和挂载点信息。命令及结果如下:
phl@kernelnewbies:~/hds$ sudo unshare --uts --mount /bin/bash
root@kernelnewbies:~/hds# cat /proc/self/mountinfo | grep hd
739 570 7:18 / /home/phl/hds/hd1 rw,relatime - ext2 /dev/loop18 rw
root@kernelnewbies:~/hds# readlink /proc/$$/ns/mnt
mnt:[4026532180]从结果我们可以看到,新mount namespace中的挂载点信息与全局mountnamespace中的挂载点信息基本一致,一些挂载选项(如传播状态)变化了。新的mount namespace id与全局mount namespace id是不一样的。
然后,我们在新的mount namespace中挂载hd2.img到hd2目录,并查看挂载点信息。命令及结果如下:
root@kernelnewbies:~/hds# mount hd2.img hd2
root@kernelnewbies:~/hds# cat /proc/self/mountinfo | grep hd
739 570 7:18 / /home/phl/hds/hd1 rw,relatime - ext2 /dev/loop18 rw
740 570 7:19 / /home/phl/hds/hd2 rw,relatime - ext2 /dev/loop19 rw从结果我们可以看到,新mount namespace中有hd1和hd2这两个挂载点。现在启动一个新的Shell窗口,查看全局mount namespace中的挂载点信息。命令及结果如下:
phl@kernelnewbies:~/hds$ cat /proc/self/mountinfo | grep hd
556 27 7:18 / /home/phl/hds/hd1 rw,relatime shared:372 - ext2 /dev/loop18 rw从结果我们可以看到,全局mount namespace中的挂载点信息只有hd1,而没有hd2。这说明在新mount namespace中进行挂载/卸载操作不会影响其他mount namespace中的挂载点信息。
mount namespace只隔离挂载点信息,并不隔离挂载点下面的文件信息。对于多个mount namespace都能看到的挂载点,如果在一个namespace中修改了挂载点下面的文件,其他namespace也能感知到。下面,我们在新建的mount namespace中创建一个文件,命令如下:
root@kernelnewbies:~/hds# echo hello from new mount namespace > hd1/hello.txt在新启动的Shell中,查看hd1目录并读取hd1/hello.txt文件。命令及结果如下:
phl@kernelnewbies:~/hds$ tree hd1
hd1
├── hello.txt
└── lost+found [error opening dir]
1 directory, 1 file
phl@kernelnewbies:~/hds$ cat hd1/hello.txt
hello from new mount namespace从结果我们可以看到,在全局mount namespace中,我们可以读取到在新建的mount namespace中创建的文件。
docker.sh
有了以上关于mount namespace的知识,我们就可以将mount namespace加入到docker.sh中了。mount namespace将放在docker.sh中,带下划线的行是我们为实现mount namespace而修改的代码。修改后的docker.sh脚本如下:
...
unshare --uts --mount ./container.sh从上述代码我们可以看到,我们仅仅是在调用unshare时加入–mount选项,就可为docker.sh引入了mount namespace功能。
pid namespace
unshare的–fork选项
unshare有一个选项–fork,当执行unshare时,如果没有这个选项,unshare会直接exec新命令,也就是说unshare变成了新命令。如果带有–fork选项,unshare会fork一个子进程,该子进程exec新命令,unshare是该子进程的父进程。我们分别不带–fork和带–fork来执行unshare,然后查看进程之间的关系。
首先,我们不带–fork选项执行unshare,并查看当前Shell的进程id。命令及结果如下:
phl@kernelnewbies:~$ sudo unshare --uts /bin/bash
root@kernelnewbies:~/hds# echo $$
11699此时unshare会创建一个新的uts namespace,然后exec /bin/bash。我们启动一个新Shell,然后使用pstree查看进程间关系,命令及结果如下:
phl@kernelnewbies:~/hds$ pstree -p | grep 11699
sudo(11698)---bash(11699)从结果我们可以看到,sudo fork出一个子进程,该子进程执行unshare。unshare创建了新uts namespace后,exec了/bin/bash,也就是说unshare变成了/bin/bash。
然后,我们带–fork选项执行unshare,并查看当前Shell的进程id。命令及结果如下:
phl@kernelnewbies:~/hds$ sudo unshare --uts --fork /bin/bash
root@kernelnewbies:~/hds# echo $$
11866此时unshare会创建一个新的uts namespace,然后fork出一个子进程,该子进程exec /bin/bash。我们启动一个新Shell,然后使用pstree查看进程间关系,命令及结果如下:
phl@kernelnewbies:~/hds$ pstree -p | grep 11866
sudo(11864)---unshare(11865)---bash(11866)从结果我们可以看到,sudo fork出一个子进程,该子进程执行命令unshare。unshare创建了新uts namespace后,fork出一个子进程,该子进程exec /bin/bash,也就是说unshare变成了新的/bin/bash进程的父进程。
pid namespace简介
pid namespace用来隔离进程pid空间,使得不同pid namespace里的进程 pid可以重复且相互之间不影响。进程所属的pid namespace在创建的时候就确定了,无法更改,因此需要–fork选项来创建一个新进程,然后将该新进程加入新建的pid namespace中。pid namespace在unshare中的选项为–pid。
unshare在创建pid namespace时需同时提供–pid与–fork选项。unshare本身会加入全局的pid namespace,其fork出的子进程会加入新建的pid namespace。
首先,我们查看全局pid namespace id,命令及结果如下:
phl@kernelnewbies:~$ sudo readlink /proc/$$/ns/pid
pid:[4026531836]然后,执行unshare命令创建一个新的pid namespace并查看该pid namespace id。命令及结果如下:
phl@kernelnewbies:~$ sudo unshare --mount --pid --fork /bin/bash
root@kernelnewbies:~# readlink /proc/$$/ns/pid
pid:[4026531836]从结果我们可以看到,新创建的进程也处于全局pid namespace中,而不是新的pid namespace。
出现这种情形是因为当前的/proc文件系统是老的。我们查看一下$$的值,命令及结果如下:
root@kernelnewbies:~# echo $$
1从结果我们可以看到,$$的值为1,但是/proc文件系统却是老的,因此我们查看的实际是init进程所属的pid namespace,当然是全局pid namespace了。
重新挂载/proc文件系统,这也是unshare执行时带–mount选项的原因,只有这样,重新挂载/proc文件系统时,不会搞乱整个系统。再次查看新进程所属的pid namespace,命令及结果如下:
root@kernelnewbies:~# mount -t proc proc /proc
root@kernelnewbies:~# readlink /proc/$$/ns/pid
pid:[4026532182]从结果我们可以看到,新进程的pid namespace与全局pid namespace的id不同。
接下来,我们再来查看一下新pid namespace中的进程信息。命令及结果如下:
root@kernelnewbies:~# ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 19:03 pts/1 00:00:00 /bin/bash
root 10 1 0 19:03 pts/1 00:00:00 ps -e从结果我们可以看到,当前pid namespace中只有2个进程,看不到全局pid namespace里面的其他进程。我们通过unshare执行的进程pid为1,也就是说该进程成了新pid namespace中的init进程。
pid嵌套
pid namespace可以嵌套,也就是说有父子关系,在当前pid namespace里面创建的所有新的pid namespace都是当前pid namespace的子pid namespace。
首先,我们创建3个嵌套的pid namespace,并查看每个pid namespace id。–mount-proc选项用于自动挂载/proc文件系统,省去了手动挂载/proc文件系统的操作。命令及结果如下:
phl@kernelnewbies:~$ sudo readlink /proc/$$/ns/pid
pid:[4026531836]
phl@kernelnewbies:~$ sudo unshare --uts --mount --pid --mount-proc --fork /bin/bash
root@kernelnewbies:~# readlink /proc/$$/ns/pid
pid:[4026532182]
root@kernelnewbies:~# unshare --uts --mount --pid --mount-proc --fork /bin/bash
root@kernelnewbies:~# readlink /proc/$$/ns/pid
pid:[4026532185]
root@kernelnewbies:~# unshare --uts --mount --pid --mount-proc --fork /bin/bash
root@kernelnewbies:~# readlink /proc/$$/ns/pid
pid:[4026532188]然后,我们启动一个新Shell,然后使用pstree查看进程间关系。命令及结果如下:
phl@kernelnewbies:~$ pstree -lp | grep unshare
sudo(12547)---unshare(12548)---bash(12549)---unshare(12579)---bash(12580)---unshare(12593)---bash(12594)使用cat /proc/[pid]/status | grep NSpid可查看某进程在当前pid namespace及子孙pid namespace中的pid。我们在全局pid namespace中查看上述各进程在各pid namespace中的pid,命令及结果如下:
phl@kernelnewbies:~$ cat /proc/12594/status | grep NSpid
NSpid: 12594 21 11 1
phl@kernelnewbies:~$ cat /proc/12593/status | grep NSpid
NSpid: 12593 20 10
phl@kernelnewbies:~$ cat /proc/12580/status | grep NSpid
NSpid: 12580 11 1
phl@kernelnewbies:~$ cat /proc/12579/status | grep NSpid
NSpid: 12579 10
phl@kernelnewbies:~$ cat /proc/12549/status | grep NSpid
NSpid: 12549 1下面我们将以上进程在各pid namespace中的pid,整理成表格。表格信息如下:
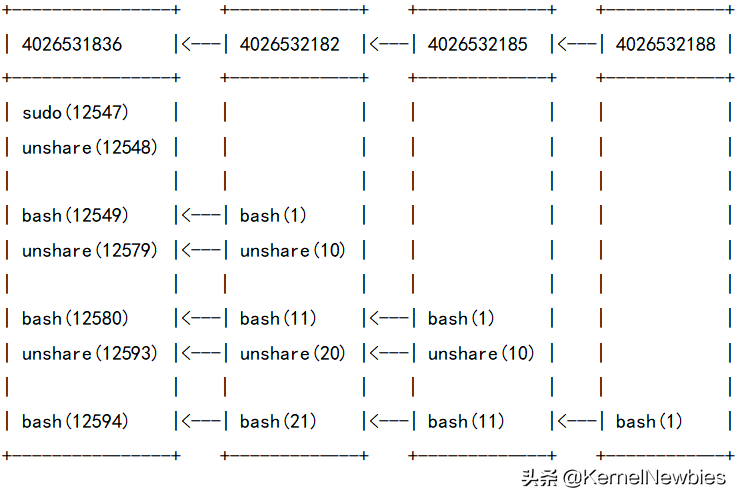
我们以最后一行为例进行介绍,最后一行有4个pid,这4个pid其实是同一个进程。这个进程在4个pid namespace中都可以被看到,且其在4个pid namespace中的pid各不相同。
docker.sh
有了以上关于pid namespace的知识,我们就可以将pid namespae加入到docker.sh中了。pid namespace将放在docker.sh中,带下划线的行是我们为实现pid namespace而修改的代码。修改后的docker.sh脚本如下:
...
unshare --uts --mount --pid --fork ./container.sh从上述代码我们可以看到,我们仅仅是在调用unshare时加入–pid和–fork选项,就可为docker.sh引入了pid namespace功能。
然后,我们需要重新挂载/proc文件系统。重新挂载/proc文件系统的功能将放在container.sh中,带下划线的行是我们为重新挂载/proc文件系统而新添的代码。修改后的container.sh脚本如下如下所示:
hostname $container
mount -t proc proc /proc
exec $program现在,我们运行docker.sh,并查看当前的进程信息。命令及结果如下:
phl@kernelnewbies:~/docker.sh$ sudo ./docker.sh -c run -m 100M -C dreamland -I ubuntu1604 -V data1 -P /bin/bash
root@dreamland:~/docker.sh# ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 17:31 pts/1 00:00:00 /bin/bash
root 16 1 0 17:31 pts/1 00:00:00 ps -ef从结果我们可看出,当前进程只有两个,不再有主机上的其他进程。
CGroups
CGroups简介
CGroups是一种将进程分组,并以组为单位对进程实施资源限制的技术。每个组都包含以下几类信息:
- 进程列表
- 资源A限制
- 资源B限制
- 资源C限制
- …
我们将以常见的CPU资源及内存资源为例进行介绍。以下的信息将使进程号为1001、1002、2008、3306的四个进程总共只能使用一个CPU核心;总共最多使用25%的CPU资源;总共最多使用100M内存,这样的一个分组被称为cgroup。
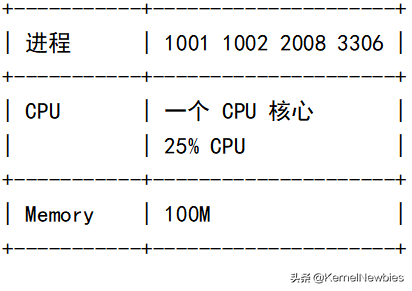
上面的介绍只是说明了要将何种资源限制施加于哪些进程,并未说明资源限制是如何施加到进程上。具体施加资源限制的过程需要subsystem来帮忙。subsystem读取cgroup中的资源限制和进程列表,然后将这些资源限制施加到这些进程上。常见的subsystem包括如下几种:
- cpu
- memory
- pids
- devices
- blkio
- net_cls
每个subsystem只读取与其相关的资源限制,然后施加到进程上。例如:memory子系统只读取内存限制,而cpu子系统只读取cpu限制。
cgroup被组织成树,如下图所示:
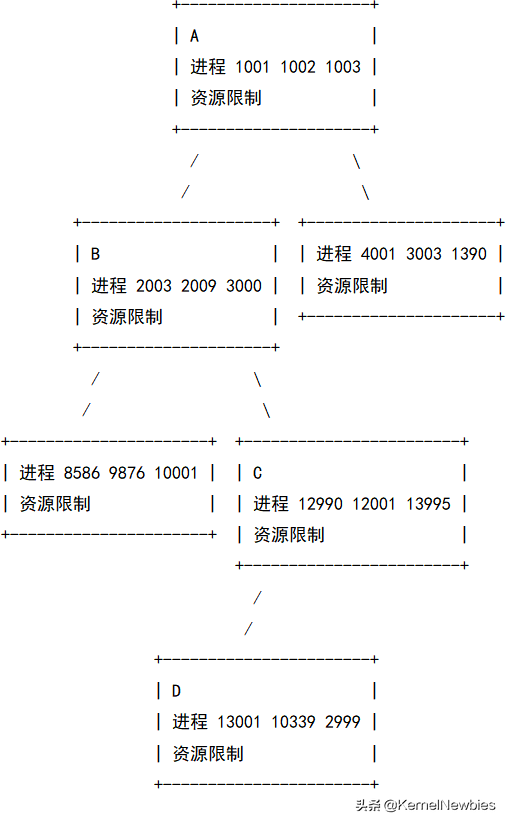
采用树状结构可以方便地实现资源限制继承,一个cgroup中的资源限制将作用于该cgroup及其子孙cgroup中的进程。例如:图中13001、10339、2999受到A、B、C、D四个cgroup中的资源限制。这样的一个树状结构被称为hierarchy。
hierarchy中包含了系统中所有的进程,它们分布于各个cgroup中。在hierarchy中,一个进程必须属于且只属于一个cgroup,这样才能保证对进程施加的资源限制不会遗漏也不会冲突。
要想让一个subsystem读取hierarchy中各cgroup的资源限制,并施加于其中的进程需要将subsystem和hierarchy关联起来。subsystem与hierarchy的关系如下:
- 系统中可以有多个hierarchy
- 一个hierarchy可以关联0个或多个subsystem,当关联0个subsystem时,该hierarchy只是对进程进行分类
- 一个subsystem最多关联到一个hierarchy,因为每个hierarchy都包含系统中所有的进程,若一个subsystem关联到了多个hierarchy,对同一进程将有多种资源限制,这是不对的
系统使用CGroups通常有两种形式:一种是创建一个hierarchy,将所有的subsystem关联到其上,在这个hierarchy上配置各种资源限制;另一种是为每一个subsystem创建一个hierarchy,并将该subsystem关联到其上,每个hierarchy只对一种资源进行限制。后一种比较清晰,得到了更普遍的采用。
CGroups不像大多数的技术那样提供API或命令之类的用户接口,而是提供给用户一个虚拟文件系统,该虚拟文件系统类型为cgroup。一个挂载后的cgroup文件系统就是一个hierarchy,文件系统中的一个目录就是一个cgroup,目录中的文件代表了进程列表或者资源限制信息。文件系统是树状结构,其各个目录之间的父子关系就代表了cgroup之间的继承关系。挂载cgroup虚拟文件系统后,通过在该文件系统上创建目录、写进程列表文件、写资源限制文件就可以操作CGroups。
下面,我们通过实验学习一下CGroups的用法。首先,我们挂载一个cgroup虚拟文件系统,该文件系统不与任何subsystem关联,仅仅是将进程进行分类。命令及结果如下:
phl@kernelnewbies:~$ mkdir -p cg/test
# -o none,name=test 表示该cgroup文件系统不与任何子系统关联
# 该文件系统用name=test来标识
phl@kernelnewbies:~$ sudo mount -t cgroup -o none,name=test test cg/test
phl@kernelnewbies:~$ tree cg/test
cg/test
├── cgroup.clone_children
├── cgroup.procs
├── cgroup.sane_behavior
├── notify_on_release
├── release_agent
└── tasks
0 directories, 6 files挂载cgroup文件系统后,该cgroup文件系统的根目录下会生成许多文件,该根目录被称为root cgroup。cgroup.procs里面存放的是当前cgroup中的所有进程id,由于该hierarchy中只有一个cgroup,所以这个文件包含了系统中所有的进程id。其他的文件与cgroups基本功能关系不大,暂时可以忽略。
在cgroup文件系统中,创建一个目录就会创建一个cgroup。下面我们将会演示如何创建下面这样的hierarchy:
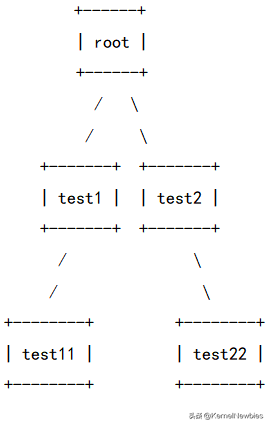
命令及结果如下:
phl@kernelnewbies:~$ sudo mkdir -p cg/test/test1/test11
phl@kernelnewbies:~$ sudo mkdir -p cg/test/test2/test22
phl@kernelnewbies:~$ tree cg/test
cg/test
├── cgroup.clone_children
├── cgroup.procs
├── cgroup.sane_behavior
├── notify_on_release
├── release_agent
├── tasks
├── test1
│ ├── cgroup.clone_children
│ ├── cgroup.procs
│ ├── notify_on_release
│ ├── tasks
│ └── test11
│ ├── cgroup.clone_children
│ ├── cgroup.procs
│ ├── notify_on_release
│ └── tasks
└── test2
├── cgroup.clone_children
├── cgroup.procs
├── notify_on_release
├── tasks
└── test22
├── cgroup.clone_children
├── cgroup.procs
├── notify_on_release
└── tasks
4 directories, 22 files从结果我们可以看到,我们创建了相应的目录后,这些目录下自动出现了包含cgroup信息的目录及文件。
删除cgroup时只需删除该cgroup所在的目录即可。下面我们将删除test11 cgroup,命令及结果如下:
phl@kernelnewbies:~$ sudo rmdir cg/test/test1/test11
phl@kernelnewbies:~$ tree cg/test
cg/test
├── cgroup.clone_children
├── cgroup.procs
├── cgroup.sane_behavior
├── notify_on_release
├── release_agent
├── tasks
├── test1
│ ├── cgroup.clone_children
│ ├── cgroup.procs
│ ├── notify_on_release
│ └── tasks
└── test2
├── cgroup.clone_children
├── cgroup.procs
├── notify_on_release
├── tasks
└── test22
├── cgroup.clone_children
├── cgroup.procs
├── notify_on_release
└── tasks
3 directories, 18 files每个cgroup下面都有一个cgroup.procs文件,该文件里面包含当前cgroup里面的所有进程id。只要将某个进程的id写入该文件,即可将该进程加入到该cgroup中。下面,我们将当前的bash加入到test22 cgroup中,命令及结果如下:
phl@kernelnewbies:~$ echo $$
3894
phl@kernelnewbies:~$ sudo sh -c "echo 3894 > cg/test/test2/test22/cgroup.procs"/proc/[pid]/cgroup包含了某个进程所在的cgroup信息。下面,我们查看一下当前bash进程所在的cgroup信息,命令及结果如下:
phl@kernelnewbies:~$ cat /proc/3894/cgroup
13:name=test:/test2/test22
12:freezer:/
11:perf_event:/
10:blkio:/user.slice
9:devices:/user.slice
8:hugetlb:/
7:cpu,cpuacct:/user.slice
6:net_cls,net_prio:/
5:memory:/user.slice
4:rdma:/
3:pids:/user.slice/user-1001.slice/session-4.scope
2:cpuset:/
1:name=systemd:/user.slice/user-1001.slice/session-4.scope
0::/user.slice/user-1001.slice/session-4.scope从结果我们可以看到,当前bash进程加入了多个cgroup,其中带下划线的行为我们刚刚加入的cgroup。
要想将hierarchy与子系统关联起来,需要在-o选项中指定子系统名称。下面演示了如何将memory子系统与新挂载的cgroup文件系统关联起来。代码如下:
phl@kernelnewbies:~$ sudo mkdir cg/memory
phl@kernelnewbies:~$ sudo mount -t cgroup -o memory memcg cg/memory由于很多发行版的操作系统已经为我们配置好了这些cgroup文件系统,我们应当直接使用这些已经挂在好的文件系统,不需要自己去挂载。
另外,当创建子进程时,子进程会自动加入父进程所在的cgroup。
限制内存
用CGroups限制内存
下面我们将介绍演示CGroups如何限制进程使用的内存资源,我们以内存为例进行讲解。
Ubuntu18.04已经为我们挂载了一个关联memory子系统的cgroup虚拟文件系统。我们用mount命令查看一下该系统挂载到了何处,命令及结果如下:
phl@kernelnewbies:~$ mount | grep cgroup
tmpfs on /sys/fs/cgroup type tmpfs (ro,nosuid,nodev,noexec,mode=755)
cgroup on /sys/fs/cgroup/unified type cgroup2 (rw,nosuid,nodev,noexec,relatime,nsdelegate)
cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,name=systemd)
cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset)
cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,pids)
cgroup on /sys/fs/cgroup/rdma type cgroup (rw,nosuid,nodev,noexec,relatime,rdma)
cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
cgroup on /sys/fs/cgroup/net_cls,net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,net_cls,net_prio)
cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpu,cpuacct)
cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,hugetlb)
cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,devices)
cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio)
cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,perf_event)
cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,freezer)该系统挂载到了/sys/fs/cgroup/memory目录下。我们在该hierarchy中创建一个test cgroup并查看该cgroup的目录结构,命令及结果如下:
phl@kernelnewbies:~$ sudo mkdir /sys/fs/cgroup/memory/test
phl@kernelnewbies:~$ tree /sys/fs/cgroup/memory/test
/sys/fs/cgroup/memory/test
├── cgroup.clone_children
├── cgroup.event_control
├── cgroup.procs
├── memory.failcnt
├── memory.force_empty
├── memory.kmem.failcnt
├── memory.kmem.limit_in_bytes
├── memory.kmem.max_usage_in_bytes
├── memory.kmem.slabinfo
├── memory.kmem.tcp.failcnt
├── memory.kmem.tcp.limit_in_bytes
├── memory.kmem.tcp.max_usage_in_bytes
├── memory.kmem.tcp.usage_in_bytes
├── memory.kmem.usage_in_bytes
├── memory.limit_in_bytes
├── memory.max_usage_in_bytes
├── memory.move_charge_at_immigrate
├── memory.numa_stat
├── memory.oom_control
├── memory.pressure_level
├── memory.soft_limit_in_bytes
├── memory.stat
├── memory.swappiness
├── memory.usage_in_bytes
├── memory.use_hierarchy
├── notify_on_release
└── tasks
0 directories, 27 files从结果我们可以看到,新建的test cgroup中有许多文件,这些文件中存放着资源限制信息。其中memory.limit_in_bytes里面存放的是该cgroup中的进程能够使用的内存额度。
下面,我们将当前bash加入到test cgroup中并查看当前bash所属的cgroup信息。命令及结果如下:
phl@kernelnewbies:~$ echo $$
2984
phl@kernelnewbies:~$ sudo sh -c "echo 2984 > /sys/fs/cgroup/memory/test/cgroup.procs"
phl@kernelnewbies:~$ cat /proc/2984/cgroup
12:devices:/user.slice
11:hugetlb:/
10:memory:/test
9:rdma:/
8:perf_event:/
7:blkio:/user.slice
6:cpu,cpuacct:/user.slice
5:pids:/user.slice/user-1001.slice/session-4.scope
4:freezer:/
3:cpuset:/
2:net_cls,net_prio:/
1:name=systemd:/user.slice/user-1001.slice/session-4.scope
0::/user.slice/user-1001.slice/session-4.scope从结果我们可以看到,当前bash所属的memory cgroup变为了/test,该目录为一个相对于root cgroup的相对路径。
然后,将100M写入test cgroup中的memory.limit_in_bytes文件中,命令如下:
phl@kernelnewbies:~$ sudo sh -c "echo 100M > /sys/fs/cgroup/memory/test/memory.limit_in_bytes"我们在当前bash中启动一个占用300M进程的stress进程,该stress进程是bash的子进程,其与bash进程都在test cgroup中。命令如下:
phl@kernelnewbies:~$ stress --vm 1 --vm-bytes 300M --vm-keep启动一个新的Shell窗口,执行top命令查看stress进程占用的内存。命令及结果如下:
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
14216 root 20 0 315440 101224 264 D 27.7 2.5 0:02.66 stress从结果我们可以看到,stress进程占用了2.5%的内存。我的电脑的内存为4G,4G * 2.5% = 100M,stress进程确实受到了cgroup中设置的内存额度的限制。
docker.sh
下有了以上关于CGroups的知识,我们就可以将限制内存的功能加入到docker.sh中了。限制内存的功能将放在container.sh中,带下划线的行是我们为实现限制内存而新添的代码。修改后的container.sh脚本如下:
hostname $container
mkdir -p /sys/fs/cgroup/memory/$container
echo $$ > /sys/fs/cgroup/memory/$container/cgroup.procs
echo $memory > /sys/fs/cgroup/memory/$container/memory.limit_in_bytes
mount -t proc proc /proc
exec $program首先,我们根据容器的名字创建cgroup,命令如下:
mkdir -p /sys/fs/cgroup/memory/$container然后,我们将当前bash加入到我们创建的cgroup中,命令如下:
echo $$ > /sys/fs/cgroup/memory/$container/cgroup.procs最后,我们将内存限制写入新cgroup的memory.limit_in_bytes文件中,命令如下:
echo $memory > /sys/fs/cgroup/memory/$container/memory.limit_in_bytes现在,我们运行docker.sh,并启动一个占用300M进程的stress进程。命令及结果如下:
phl@kernelnewbies:~/docker.sh$ sudo ./docker.sh -c run -m 100M -C dreamland -I ubuntu1604 -V data1 -P /bin/bash
root@dreamland:~/docker.sh# stress --vm 1 --vm-bytes 300M --vm-keep
stress: info: [12] dispatching hogs: 0 cpu, 0 io, 1 vm, 0 hdd启动一个新的Shell窗口,执行top命令查看stress进程占用的内存。命令及结果如下:
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
14216 root 20 0 315440 101224 264 D 27.7 2.5 0:02.66 stress从结果我们可以看到,容器内的stress进程只使用了100M的内存。
切换根文件系统
根文件系统
在容器技术中,根文件系统可为容器进程提供一个与主机不一致的文件系统环境。举个例子,主机为Ubuntu 18.04,创建的容器采用Ubuntu 16.04的根文件系统,那么容器运行时所用的软件及其依赖库、配置文件等都是Ubuntu 16.04的。尽管该容器使用的内核是仍旧是Ubuntu 18.04的,但应用软件的表现却与Ubuntu 16.04一致,从虚拟化的角度来说该容器就是一个Ubuntu 16.04系统。
debootstrap是Ubuntu下的一个工具,用来构建根文件系统。生成的目录符合Linux文件系统标准,即包含了/boot、/etc、/bin、/usr等目录。debootstrap的安装命令如下:
sudo apt install debootstrap下面我们通过debootstrap构建Ubuntu 16.04的根文件系统。为了清晰,我们在images目录下生成根文件系统。命令及结果如下:
phl@kernelnewbies:~/docker.sh$ mkdir images
phl@kernelnewbies:~/docker.sh$ cd images
phl@kernelnewbies:~/docker.sh/images$ sudo debootstrap --arch amd64 xenial ./ubuntu1604制作根文件系统需要从服务器下载很多文件,很耗时,请耐心等待。当文件系统制作好后,可以使用tree命令查看生成的根文件系统。命令及结果如下:
phl@kernelnewbies:~/docker.sh/images$ tree -L 1 ubuntu1604/
ubuntu1604/
├── bin
├── boot
├── dev
├── etc
├── home
├── lib
├── lib64
├── media
├── mnt
├── old_root
├── opt
├── proc
├── root
├── run
├── sbin
├── srv
├── sys
├── tmp
├── usr
└── var
20 directories, 0 files这个根文件系统与Linux系统目录很相近,我们后续的实验将使用该根文件系统。
pivot_root
pivot_root命令用于切换根文件系统,其使用方式如下:
pivot_root new_root put_oldpivot_root将当前进程的根文件系统移至put_old目录并使new_root目录成为新的根文件系统。
下面我们将通过实验学习pivot_root的使用方法。为了简单,我们在一个新的mount namespace下进行实验。首先,我们创建一个新的mount namespace,命令及结果如下:
phl@kernelnewbies:~/docker.sh/images$ sudo unshare --mount /bin/bash
root@kernelnewbies:~/docker.sh/images#在我们的实验中,我们的根文件系统将挂载在ubuntu1604目录,而老的根文件系统将被移动到ubuntu1604/old_root目录下。我们先创建old_root目录,命令如下:
root@kernelnewbies:~/docker.sh/images# mkdir -p ubuntu1604/old_root/
由于pivot_root命令要求老的根目录和新的根目录不能在同一个挂载点下,因此我们通过bind mount将ubuntu1604目录变成一个挂载点。命令及结果如下:
root@kernelnewbies:~/docker.sh/images# mount --bind ubuntu1604 ubuntu1604
root@kernelnewbies:~/docker.sh/images# cat /proc/self/mountinfo | grep ubuntu1604
624 382 8:1 /home/phl/docker.sh/images/ubuntu1604 /home/phl/docker.sh/images/ubuntu1604 rw,relatime - ext4 /dev/sda1 rw,errors=remount-ro准备好切换根文件系统所需要的条件后,我们调用pivot_root切换根文件系统。命令及结果如下:
root@kernelnewbies:~/docker.sh/images# cd ubuntu1604/
root@kernelnewbies:~/docker.sh/images/ubuntu1604# pivot_root . old_root/此时,已完成根文件系统的切换,/proc文件系统也被挪到了
/home/phl/docker.sh/images/ubuntu1604/old_root/proc,也就是说当前没有/proc文件系统,因此,我们无法查看挂载点信息,自然也无法执行一些依赖于/proc文件系统的操作。我们需要重新挂载/proc文件系统。命令如下:
root@kernelnewbies:~/docker.sh/images/ubuntu1604# mount -t proc proc /proc重新挂载/proc文件系统后,我们就可以查看当前的挂载点信息了。通过读取/proc/self/mountinfo文件来查看系统的挂载点信息。命令及结果如下:
root@kernelnewbies:~/docker.sh/images/ubuntu1604# cat /proc/self/mountinfo
382 624 8:1 / /old_root rw,relatime - ext4 /dev/sda1 rw,errors=remount-ro
...
624 381 8:1 /home/phl/docker.sh/images/ubuntu1604 / rw,relatime - ext4 /dev/sda1 rw,errors=remount-ro
625 624 0:5 / /proc rw,relatime - proc proc rw此时的挂载点很多,为了方便查看,此处只保留了一些主要的挂载点信息。这些挂载点信息包括/、/proc、/old_root。/old_root为老的根文件系统,我们需要将其卸载。命令及结果如下:
root@kernelnewbies:~/docker.sh/images/ubuntu1604# umount -l /old_root/卸载掉老的根文件系统后,我们再查看系统的挂载点信息。命令及结果如下:
root@kernelnewbies:~/docker.sh/images/ubuntu1604# cat /proc/self/mountinfo
624 381 8:1 /home/phl/docker.sh/images/ubuntu1604 / rw,relatime - ext4 /dev/sda1 rw,errors=remount-ro
625 624 0:5 / /proc rw,relatime - proc proc rw此时,挂载点信息中只有/、/proc,不再有主机的挂载点信息。
docker.sh
有了以上关于切换根文件系统的知识,我们就可以将切换根文件系统的功能加入到docker.sh中了。切换根文件系统的功能将放在container.sh中,带下划线的行是我们为实现切换根文件系统而新添的代码。修改后的container.sh脚本如下:
#!/bin/bash
hostname $container
mkdir -p /sys/fs/cgroup/memory/$container
echo $$ > /sys/fs/cgroup/memory/$container/cgroup.procs
echo $memory > /sys/fs/cgroup/memory/$container/memory.limit_in_bytes
mkdir -p images/$image/old_root
mount --bind images/$image images/$image
cd images/$image
pivot_root . ./old_root
mount -t proc proc /proc
umount -l /old_root
exec $program首先,我们在新的根文件系统目录中创建挂载老的根文件系统的目录。命令如下:
mkdir -p images/$image/old_root然后,我们将新根文件系统目录bind mount成一个挂载点。命令如下:
mount --bind images/$image images/$image然后,我们切换根文件系统。命令如下:
cd images/$image
pivot_root . ./old_root最后,我们重新挂载/proc文件系统,然后卸载掉老的根文件系统。命令如下:
mount -t proc proc /proc
umount -l /old_root现在,我们运行docker.sh,并查看当前的发行版信息。命令及结果如下:
phl@kernelnewbies:~/docker.sh$ sudo ./docker.sh -c run -m 100M -C dreamland -I ubuntu1604 -V data1 -P /bin/bash
root@dreamland:/# cat /etc/issue
Ubuntu 16.04 LTS \n \l从结果我们可以看出,读出的发行版信息是Ubuntu 16.04 LTS \n \l,而非主机的Ubuntu 18.04.3 LTS \n \l。这说明当前使用的根文件系统确实是ubuntu16.04目录下的根文件系统,而非主机的根文件系统。
我们再查看一下当前的挂载点信息,看看是否只有/与/proc。命令及结果如下:
root@dreamland:/# cat /proc/self/mountinfo
625 381 8:1 /home/phl/docker.sh/images/ubuntu1604 / rw,relatime - ext4 /dev/sda1 rw,errors=remount-ro
626 625 0:52 / /proc rw,relatime - proc proc rw从结果我们可看出,当前挂载点信息中只有/、/proc,不再有主机的挂载点信息。
通过根文件系统,我们实现了在容器中虚拟出与主机不一样的操作系统的功能。
联合加载
联合加载简介
联合加载指的是一次同时加载多个文件系统,但是在外面看起来只能看到 一个文件系统。联合加载会将各层文件系统叠加到一起,这样最终的文件系统会 包含所有底层的文件和目录。
联合加载的多个文件系统中有一个是可读写文件系统,称为读写层,其他文件系统是只读的,称为只读层。当联合加载的文件系统发生变化时,这些变化都应用到这个读写层。比如,如果想修改一个文件,这个文件首先会从只读层复制到读写层。原只读层中的文件依然存在,但是被读写层中的该文件副本所隐藏。我们以后读写该文件时,都是读写的该文件在读写层中的副本。这种机制被称为 写时复制。
我们之前实现的docker.sh,有一个很大的缺陷。那就是,如果使用相同的根文件系统同时启动多个容器的实例,那么,这些容器实例使用的根文件系统位于同一个目录。我们在不同的容器实例对根文件系统所作的修改,这些容器彼此之间都可以看到,甚至一个容器可以覆覆盖另一个容器所作的修改。同时,容器实例退出时,对根文件系统所作的修改也直接作用于其所使用的根文件系统。当我们使用该根文件系统再次启动容器实例时,新启动的容器实例也可以看到以前的这些修改。例如,我们用ubuntu1604根文件系统启动两个容器实例,命令如下:
phl@kernelnewbies:~/docker.sh$ sudo ./docker.sh -c run -m 100M -C dreamland -I ubuntu1604 -V data1 -P /bin/bash
phl@kernelnewbies:~/docker.sh$ sudo ./docker.sh -c run -m 100M -C dreamland2 -I ubuntu1604 -V data1 -P /bin/bash这两个容器实例对根文件系统做的修改彼此都可以看到。容器实例退出时,这些修改也被保存了下来,当用ubuntu1604根文件系统启动新的容器实例时,新实例也可看到以前实例所做的修改。
如果容器使用的根文件系统是一个联合加载的文件系统,原先的根文件系统作为一个只读层,再添加一个读写层,那么,在容器内所作的修改都将只作用于读写层。为了区分,我们以后称ubuntu1604目录下的根文件系统为镜像。而我们可以为每一个容器实例指定一个唯一的读写层目录,这样的话,多个容器实例就可以使用同一个镜像,容器内所作的修改不会影响彼此,也不会影响到以后启动的容器实例。例如:
phl@kernelnewbies:~/docker.sh$ sudo ./docker.sh -c run -m 100M -C dreamland -I ubuntu1604 -V data1 -P /bin/bash
phl@kernelnewbies:~/docker.sh$ sudo ./docker.sh -c run -m 100M -C dreamland2 -I ubuntu1604 -V data1 -P /bin/bash我们使用ubuntu1604镜像启动了两个容器示例,并在容器实例里进行读写操作。这两个容器实例的读写层目录是不一样的,在容器实例中所作的修改只作用于各自的读写层,彼此之间不会影响,当然更不会影响到后续启动的容器实例。
AUFS
AUFS是一个实现了联合加载功能的文件系统。我们将采用AUFS实现docker.sh中的联合加载功能。
下面,我们将通过实验演示一下AUFS文件系统的用法。首先,我们准备需要用到的目录及文件。命令及结果如下:
phl@kernelnewbies:~$ mkdir aufs
phl@kernelnewbies:~$ cd aufs/
phl@kernelnewbies:~/aufs$ mkdir rw r1 r2 union
phl@kernelnewbies:~/aufs$ echo hello r1 > r1/hellor1.txt
phl@kernelnewbies:~/aufs$ echo hello r2 > r2/hellor2.txt
phl@kernelnewbies:~/aufs$ echo hello rw > rw/hellorw.txt下表列出了各个目录的作用。列表如下:
- rw为aufs文件系统的读写层目录
- r1为aufs文件系统的只读层目录
- r2为aufs文件系统的只读层目录
- union为挂载点,联合加载的aufs文件系统挂载于此目录
下面我们将rw、r1、r2联合加载到union目录。命令如下:
phl@kernelnewbies:~/aufs$ sudo mount -t aufs -o dirs=rw:r1:r2 none union- -t aufs表示要挂载的文件系统类型为AUFS
- -o dirs=rw:r1:r2表示要将哪些目录加载到afus文件系统中,多个目录之间以:分隔。目录列表中的第一个目录表示读写层目录
- union表示aufs文件系统要挂载的目录
挂载好AUFS文件系统后,我们进入该文件系统,查看其内容。命令及结果如下:
phl@kernelnewbies:~/aufs$ cd union/
phl@kernelnewbies:~/aufs/union$ ls
hellor1.txt hellor2.txt hellorw.txt从输出结果来看,rw、r1、r2目录下的内容全部出现在了AUFS文件系统中,该文件系统由rw、r1、r2目录叠加而成。
然后,我们修改这些文件,看看原始的rw、r1、r2目录下的文件是否更改。命令及结果如下:
phl@kernelnewbies:~/aufs/union$ echo hello to r1 from union > hellor1.txt
phl@kernelnewbies:~/aufs/union$ echo hello to r2 from union > hellor2.txt
phl@kernelnewbies:~/aufs/union$ echo hello to rw from union > hellorw.txt我们返回到aufs目录,直接查看aufs目录下的内容。命令及结果如下:
phl@kernelnewbies:~/aufs$ tree .
.
├── r1
│ └── hellor1.txt
├── r2
│ └── hellor2.txt
├── rw
│ ├── hellor1.txt
│ ├── hellor2.txt
│ └── hellorw.txt
└── union
├── hellor1.txt
├── hellor2.txt
└── hellorw.txt
4 directories, 8 files从输出结果我们可以看到,我们修改的hellor1.txt和hellor2.txt文件分别被拷贝了一份放在读写层目录rw中。我们查看一下这些文件的内容,命令及结果如下:
phl@kernelnewbies:~/aufs$ cat r1/hellor1.txt
hello r1
phl@kernelnewbies:~/aufs$ cat r2/hellor2.txt
hello r2
phl@kernelnewbies:~/aufs$ cat rw/hellor1.txt
hello to r1 from union
phl@kernelnewbies:~/aufs$ cat rw/hellor2.txt
hello to r2 from union
phl@kernelnewbies:~/aufs$ cat rw/hellorw.txt
hello to rw from union从输出结果我们看到,用户修改只读层r1、r2中的文件时,这些文件被复制到了读写层,我们修改的是读写层的副本,原只读层中的文件没有变化。用户修改读写层rw中的文件时,修改直接作用于这些文件本身。
docker.sh
在继续之前,我们需要将上一章在ubuntu1604根文件系统中创建的old_root目录删除掉,以保证该根文件系统跟刚制作好时一样。命令及结果如下:
phl@kernelnewbies:~/docker.sh$ sudo rm -rf images/ubuntu1604/old_root
有了以上关于联合加载的介绍,我们就可以将联合加载功能加入到docker.sh中了。联合加载功能将放在container.sh脚本中,带下划线的行是我们为实现联合加载功能而新添的代码。修改后的container.sh如下:
#!/bin/bash
hostname $container
mkdir -p /sys/fs/cgroup/memory/$container
echo $$ > /sys/fs/cgroup/memory/$container/cgroup.procs
echo $memory > /sys/fs/cgroup/memory/$container/memory.limit_in_bytes
mkdir -p $container/rwlayer
mount -t aufs -o dirs=$container/rwlayer:./images/$image none $container
mkdir -p $container/old_root
cd $container
pivot_root . ./old_root
mount -t proc proc /proc
umount -l /old_root
exec $program首先,我们根据容器的名字创建联合加载需要的读写层目录及文件系统挂载目录。命令如下:
mkdir -p $container/rwlayer假如我们传递的容器的名字为dreamland,将创建以下目录:
phl@kernelnewbies:~/docker.sh$ tree dreamland/
dreamland/
└── rwlayer其中dreamland/rwlayer目录为创建的AUFS文件系统的读写层,dreamland目录为AUFS文件系统的挂载点。
然后我们将镜像目录、读写层目录联合加载到挂载点目录。命令如下:
mount -t aufs -o dirs=$container/rwlayer:./images/$image none $container假如容器名字为dreamland,使用的镜像为ubuntu1604根文件系统,dreamland/rwlayer、images/ubuntu1604将被联合加载的dreamland目录。其中,dreamland/rwlayer为AUFS文件系统的读写层,images/ubuntu1604为AUFS文件系统的只读层。
之前我们将老的根文件系统挪到了rootfs/old_root,rootfs代表一个具体的镜像目录。创建old_root目录时直接修改了该镜像。下面我们将老的根文件系统的挂载点目录放在AUFS文件系统中,并将老的根文件系统挪到此处。命令如下:
mkdir -p $container/old_root
cd $container
pivot_root . ./old_root此时,$container目录本身就是一个挂载点,挂载了AUFS文件系统。因此下面的代码就被移除了:
mount --bind images/$image images/$image现在,我们运行docker.sh,并在/root下创建一个文件。命令及结果如下:
phl@kernelnewbies:~/docker.sh$ sudo ./docker.sh -c run -m 100M -C dreamland -I ubuntu1604 -V data1 -P /bin/bash
root@dreamland:/# cd /root
root@dreamland:/root# ls
root@dreamland:/root# cat /etc/issue > hello.txt
root@dreamland:/root# cat hello.txt
Ubuntu 16.04 LTS \n \l启动一个新的Shell窗口,查看一下该容器使用的AUFS文件系统。命令及结果如下:
phl@kernelnewbies:~/docker.sh$ sudo tree dreamland/
dreamland/
└── rwlayer
├── old_root
└── root
└── hello.txt
2 directories, 1 file从结果我们可以看到,我们新建的文件及创建的老根文件系统的挂载点目录都出现在了读写层。我们再查看一下新创建的文件。命令及结果如下:
phl@kernelnewbies:~/docker.sh$ sudo cat dreamland/rwlayer/root/hello.txt
Ubuntu 16.04 LTS \n \l文件内容是Ubuntu 16.04的发行版信息。
通过联合加载,我们实现了在容器中的读写不会影响使用的镜像。这样使用ubuntu1604镜像创建多个容器时,彼此之间就不会相互影响了。
卷
卷简介
卷是容器内的一个目录,这个目录可以绕过联合文件系统,提供数据共享(容器所使用的的联合文件系统不应该被主机或其他容器访问)与数据持久化的功能。
举个例子,假如容器有个目录为/data的卷,我们向这个卷写入的内容不会出现在联合文件系统的读写层,而是直接出现在这个目录里。主机与其他容器也可以访问该目录,从而达到数据共享与数据持久化的目的。
卷位于联合文件系统中,通常来说写入该目录的内容会被写入容器的读写层中,那么怎样才能是写入卷的目录直接出现在该目录中,而不是容器读写层呢?其实方法很简单,只要我们将该目录变成一个挂载点就行,变成挂载点后,这个目录中的内容就不属于联合文件系统了,写入该目录的内容自然会保存在挂载到该挂载点的设备中。
docker.sh
有了以上关于卷的介绍,我们就可以将卷功能加入到docker.sh中了。卷功能将放在container.sh脚本中,带下划线的行是我们为实现卷功能而新添的代码。修改后的container.sh脚本如下:
#!/bin/bash
hostname $container
mkdir -p /sys/fs/cgroup/memory/$container
echo $$ > /sys/fs/cgroup/memory/$container/cgroup.procs
echo $memory > /sys/fs/cgroup/memory/$container/memory.limit_in_bytes
mkdir -p $container/rwlayer
mount -t aufs -o dirs=$container/rwlayer:./images/$image none $container
mkdir -p $volume
mkdir -p $container/$volume
mount --bind $volume $container/$volume
mkdir -p $container/old_root
cd $container
pivot_root . ./old_root
mount -t proc proc /proc
umount -l /old_root
exec $program首先,我们根据卷的名字创建主机卷目录,我们在容器内部对卷的修改,都将作用于此目录。命令如下:
mkdir -p $volume然后,我们在容器内部创建同名卷目录,该目录本身会出现在容器的读写层中,因为该目录是在AUFS文件系统中创建的。因为
mkdir -p $container/$volume将主机上的卷目录bind mount到容器内部的卷目录上,这样容器内部对卷目录的修改,都将作用于主机卷目录。命令如下:
mount --bind $volume $container/$volume现在,我们运行docker.sh,并在卷目录(/data1)中创建一个文件。命令及结果如下:
phl@kernelnewbies:~/docker.sh$ sudo ./docker.sh -c run -m 100M -C dreamland -I ubuntu1604 -V data1 -P /bin/bash
root@dreamland:/# cd /data1
root@dreamland:/data1# echo "hello to data1 volume from ubuntu16.04" >> hello.txt启动一个新的Shell窗口,查看一下该容器使用的AUFS文件系统中的内容。命令及结果如下:
phl@kernelnewbies:~/docker.sh$ sudo tree dreamland/
dreamland/
└── rwlayer
├── data1
├── old_root
└── root
└── hello.txt
4 directories, 1 file从结果我们可以看到,我们使用的卷目录被创建在了容器的读写层,但是我们在卷目录中新建的文件却没有出现在读写层中。
我们再来查看一下主机卷目录的内容。命令及结果如下:
phl@kernelnewbies:~/docker.sh$ sudo tree data1/
data1/
└── hello.txt
0 directories, 1 file从结果我们可以看到,在容器内部对卷目录的修改直接作用在了主机上的卷目录。我们再来查看一下主机卷目录下hello.txt中的内容。命令及结果如下:
phl@kernelnewbies:~/docker.sh$ sudo cat data1/hello.txt
hello to data1 volume from ubuntu16.04从结果我们可以看到,该文件的内容与我们在容器内部写入hello.txt的内容一致。
通过卷目录,我们实现了容器之间数据共享与数据持久化的功能。
后记
至此,我们通过一系列的实验对docker的底层技术有了一个感性的认识。我们在使用docker时,也能够对其是如何运作的有了一个大致的了解。当然,这对于掌握docker技术来说还远远不够,有很多知识我们没有涉及,例如user namespace、容器安全、其他的CGroups、虚拟网络等。
编辑整理 ScratchLab
系列教程
Docker系列
- Docker使用简明教程
- 使用jeckett,sonarr,iyuu,qt,emby打造全自动追剧流程
- 为知笔记私有化Docker部署
- Earthly 一个更加强大的镜像构建工具
- 使用 Shell 脚本实现一个简单 Docker
- 如何使用Traefik V2 在Ubuntu20.04 上面来做 Dockers
- 通过IPV6访问Qnap NAS中Docker的服务
Hexo系列
[十万字图文教程]基于Hexo的matery主题搭建博客并深度优化完全一站式教程
- Hexo Docker环境与Hexo基础配置篇
- hexo博客自定义修改篇
- hexo博客网络优化篇
- hexo博客增强部署篇
- hexo博客个性定制篇
- hexo博客常见问题篇
- hexo博客博文撰写篇之完美笔记大攻略终极完全版
- Hexo Markdown以及各种插件功能测试
- markdown 各种其它语法插件,latex公式支持,mermaid图表,plant uml图表,URL卡片,bilibili卡片,github卡片,豆瓣卡片,插入音乐和视频,插入脑图,插入PDF,嵌入iframe
- 在 Hexo 博客中插入 ECharts 动态图表
- 使用nodeppt给hexo博客嵌入PPT演示
- GithubProfile美化与自动获取RSS文章教程
- Vercel部署高级用法教程
- webhook部署Hexo静态博客指南
- 在宝塔VPS上面采用docker部署waline全流程图解教程
- 自建Umami访问统计服务并统计静态博客UV/PV
笔记系列
- 完美笔记进化论
- hexo博客博文撰写篇之完美笔记大攻略终极完全版
- Joplin入门指南&实践方案
- 替代Evernote免费开源笔记Joplin-网盘同步笔记历史版本Markdown可视化
- Joplin 插件以及其Markdown语法。All in One!
- Joplin 插件使用推荐
- 为知笔记私有化Docker部署
Gitbook使用系列
- GitBook+GitLab撰写发布技术文档-Part1:GitBook篇
- GitBook+GitLab撰写发布技术文档-Part2:GitLab篇
- 自己动手制作电子书的最佳方式(支持PDF、ePub、mobi等格式)



